Introduction

Manually annotating object segmentation masks is very time-consuming. While interactive segmentation methods offer a more efficient alternative, they become unaffordable at a large scale because the cost grows linearly with the number of annotated masks. In this paper, we propose a highly efficient annotation scheme for building large datasets with object segmentation masks. At a large scale, images contain many object instances with similar appearance. We exploit these similarities by using hierarchical clustering on mask predictions made by a segmentation model. We propose a scheme that efficiently searches through the hierarchy of clusters and selects which clusters to annotate. Humans manually verify only a few masks per cluster, and the labels are propagated to the whole cluster. Through a large-scale experiment to populate 1M unlabeled images with object segmentation masks for 80 object classes, we show that (1) we obtain 1M object segmentation masks with an total annotation time of only 290 hours; (2) we reduce annotation time by 76x compared to manual annotation; (3) the segmentation quality of our masks is on par with those from manually annotated datasets.
Manual Annotation is expensive!
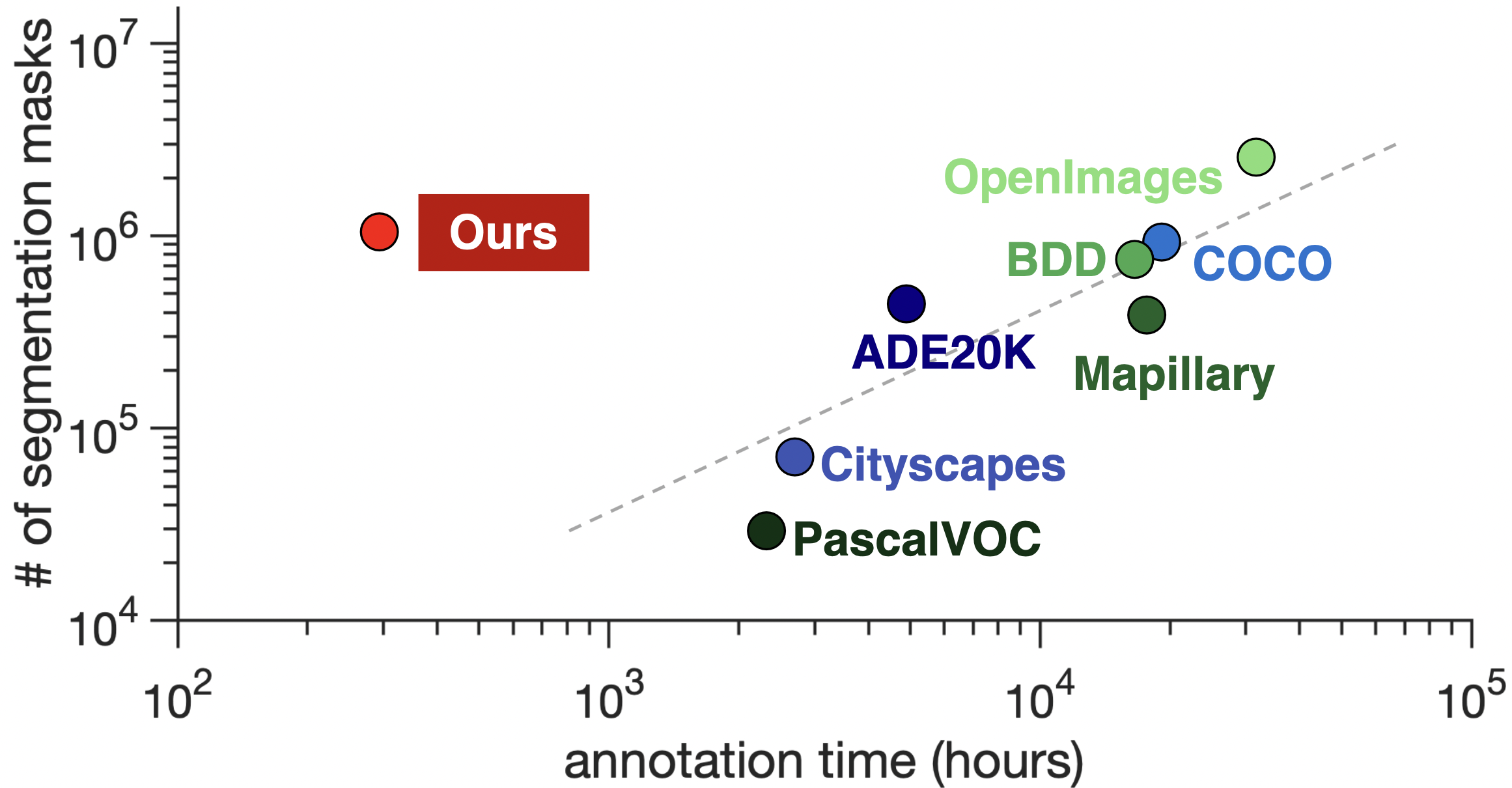
Manual annotation for instance segmentation is expensive as it requires humans to draw a detailed outline around every object in an image. For example, annotating COCO required 80 seconds per mask, an image in Cityscapes took 1.5 hours, and annotating ADE20K by a single annotator took several years. At this pace, constructing a dataset with 10M masks would require more than 200k hours and cost over $2M. An alternative is interactive segmentation, where the human interaction is much faster (e.g., boxes, scribbles, clicks). Given this interaction, these methods infer the final object mask. They offer substantial gains in annotation time and can lead to larger datasets. However, because annotators intervene on every object, the cost grows linearly with the number of annotations and therefore, at a larger scale, they become unaffordable.
Proposed Method
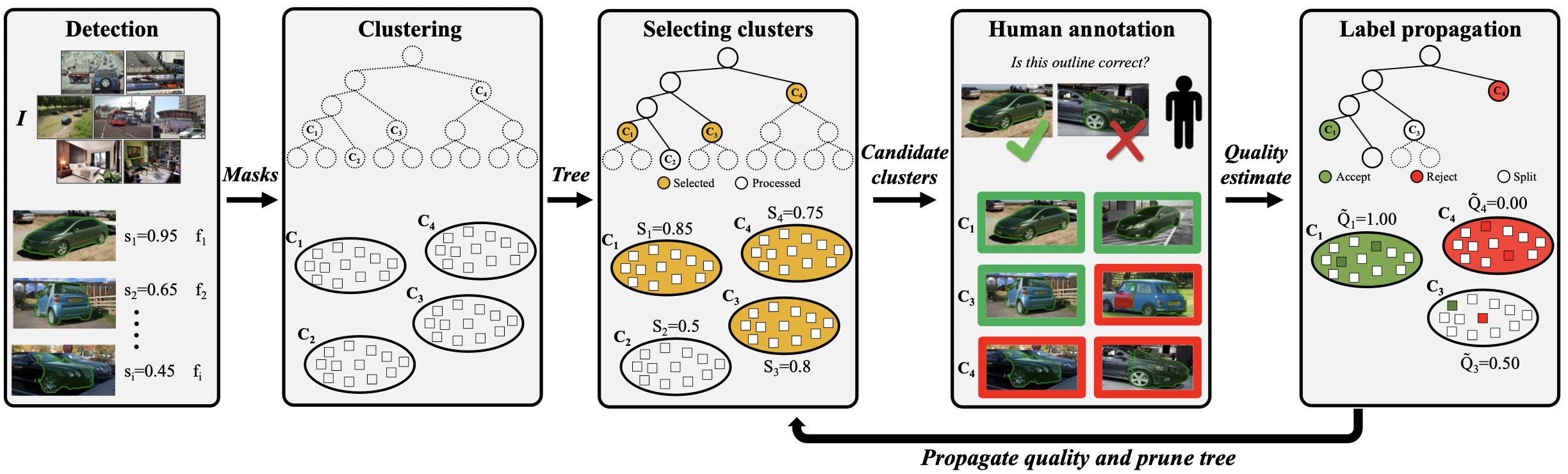
Given a small set of manually annotated images with segmentation masks and a large set of unlabeled images, our goal is to populate the unlabeled set with high-quality masks using as little human intervention as possible. Our pipeline consists of five steps: (a) Detection: we deploy an instance segmentation model on an unlabeled set to obtain segmentation masks. (b) Clustering: class-specific masks are hierarchically clustered to obtain a tree. (c) Selecting clusters: we efficiently search the tree and select candidate clusters that are likely to contain high-quality masks. (d) Human annotation: for each candidate cluster, we sample a few masks and ask annotators to verify whether they are correct or not. We use these labels to estimate the quality of the clusters. (e) Propagation: If the estimated quality is very high or very low (i.e, the cluster almost exclusively contains correct or wrong masks), we propagate the verification labels to the whole cluster and set it as a leaf. Otherwise, we further split it. We repeat (c), (d) and (e) to discover high- quality clusters with as few questions as possible.
Simulated Results
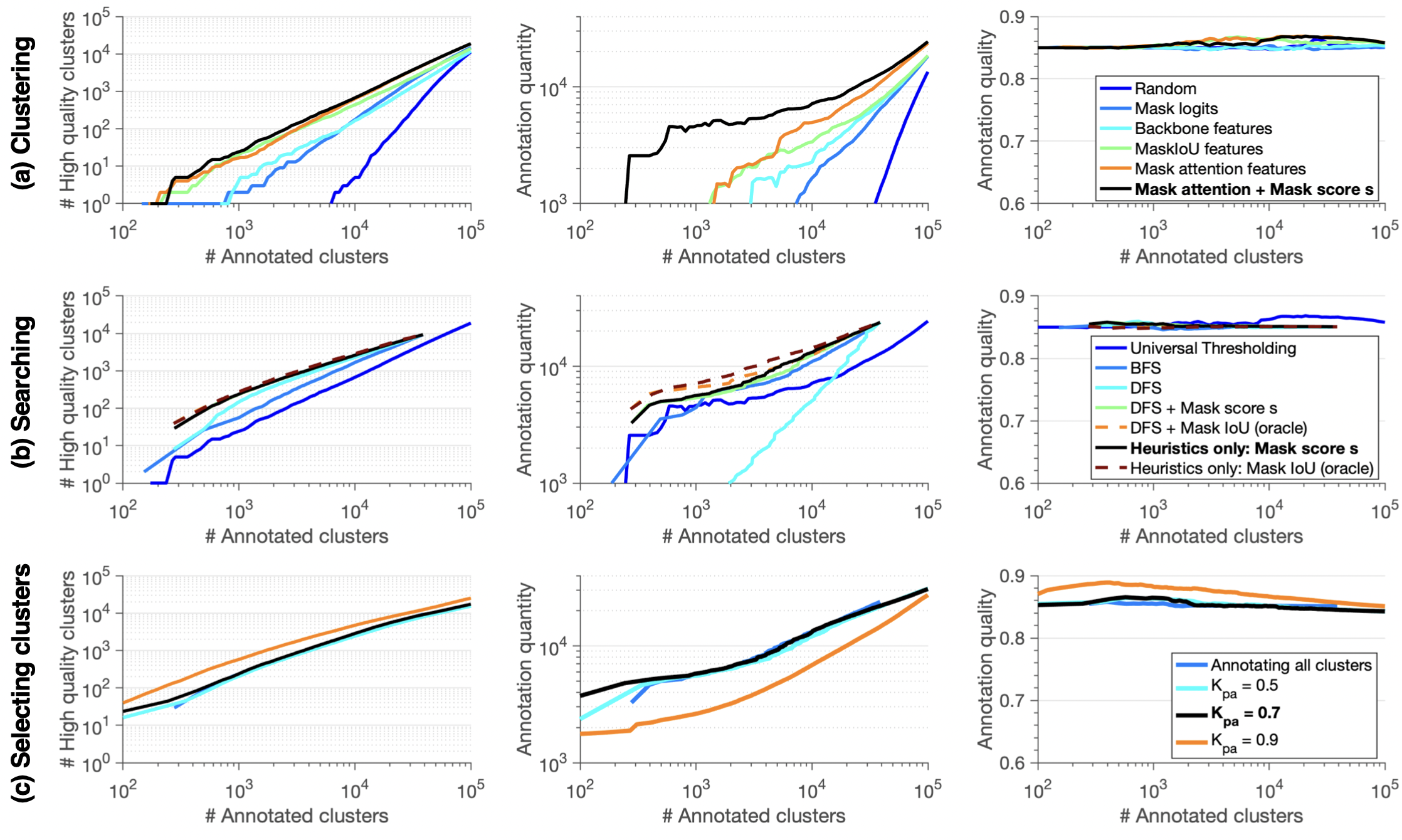
We perform simulated experiments to explore different design choices for each step of our pipeline and find parameters to minimize the annotation cost given a desired annotation quality. We perform experiments on ADE20K and show the number of high-quality clusters, the annotation quantity and the annotation quality versus the number of annotated clusters in log-log scale. (a) Clustering: The effect of using different feature representations F to construct T. (b) Searching: The effect of using different search algorithms when searching the tree T. (c) Selecting clusters: The effect of actively selecting clusters to annotate using different Kpa values. The black lines correspond to the best result in each row.
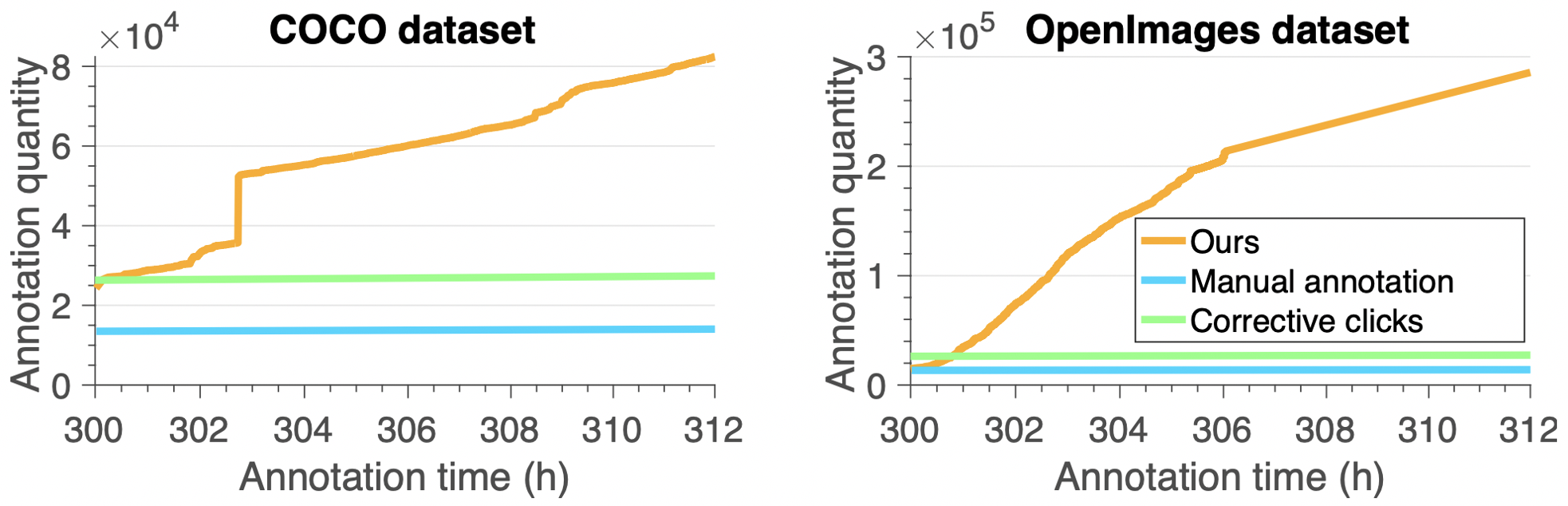
We also conduct simulated experiments on COCO and OpenImages. We follow the setting of the ADE20K experiments exactly without tuning any parameters and train our initial segmentation model on 2k COCO images (80 classes). We run our pipeline on two unlabeled sets of images: (a) the remaining 121k COCO images, and (b) the OpenImages subset with a GT in the 60 COCO classes that overlap with the 350 OpenImages ones (316k images). We obtain (a) 86k COCO and (b) 270k OpenImages annotations with only 12 h (+300 h to annotate the initial set). With 312 annotation hours, we obtain 14k instances with manual annotations and 28k with corrective clicks in either dataset Our time saving on OpenImages is 19x with respect to manual annotation. The quality of our masks is 84.6% on COCO. Benenson et. al. (corrective clicks) reports 82.0% for manual annotation and 84.0% for corrective clicks on a subset of COCO annotated with free-painting annotations. On OpenImages, we obtain 85.0% on the validation and test set vs 86.0% with corrective clicks.
Large-scale Annotation Experiment

We conduct a large-scale experiment with real annotators on Amazon Mechanical Turk (AMT) to obtain object segmentation masks using our framework with a fixed annotation budget. We use 1M images from the trainval set of the Places dataset as our unlabeled set and using our method we populate it with high-quality masks for 80 object classes. We run in total 191,929 verification questions on AMT, resulting in 730 high quality clusters. We accept in total 993,677 high quality object segmentation masks, which form our annotated dataset. The mean response time of the annotators is 1.4 s per binary question. The total time of the verification including quality control is 73 hours. Adding this time to the overhead for segmenting the initial set results in 290 annotation hours or less than $3,000. Note that manually drawing 1M polygons would require 22k hours and cost over $200k. Our framework leads to a 76x speed up in time compared to manual annotation. To evaluate the segmentation quality (SQ) of our masks, we randomly select 1,142 images from the unlabeled Places pool and an expert annotator manually draws accurate polygons around each instance. We achieve an SQ of 81.4%. The quality of our masks is on par with that of other datasets (e.g. ADE20K, COCO, Cityscapes, LVIS, OpenImages).
Paper

Bibtex
Acknowledgments
This work is supported by the Mitsubishi Electric Research Laboratories. We thank V. Kalogeiton for helpful discussion and proofreading.